Bimanual Robot Manipulation with Diffusion Policy
End-to-end imitation learning on the AgileX Cobot Magic dual-arm platform
Implemented a complete end-to-end diffusion policy pipeline for bimanual robot manipulation on the AgileX Cobot Magic platform, covering the full stack from teleoperation data collection through model training to real-time autonomous inference. The system uses a master-slave arm configuration with multi-camera observations to learn coordinated dual-arm manipulation tasks from human demonstrations.
Hardware Platform
The system consists of four Piper 6-DOF robotic arms (two master, two slave) communicating over CAN bus at 1 kHz, with three Intel RealSense cameras providing synchronized RGB-D observations (overhead, left wrist, right wrist). Each arm has a 1.5 kg payload capacity, 626 mm reach, and 0.1 mm repeatability.
Data Collection via Teleoperation
In data collection mode (_mode:=0 for master, _mode:=1 for slave), a human operator manipulates the master arms while the slave arms mirror the motion in real-time. At each timestep, the system records:
- Multi-view RGB-D frames from three cameras
- 14-dimensional joint states (7 per arm: 6 joints + 1 gripper)
- Action labels derived from the demonstrated trajectory
Demonstrations are stored as ROS bags and post-processed into HDF5 datasets for training.
Diffusion Policy Architecture
The model learns to reverse a noise corruption process, iteratively denoising random Gaussian noise into coherent action sequences conditioned on multi-modal observations.
Forward Process
During training, noise is added to ground-truth actions following a variance schedule:
where \(\bar{\alpha}_t = \prod_{i=1}^{t} (1 - \beta_i)\) is the cumulative noise schedule with \(\beta_t\) linearly interpolated from \(10^{-4}\) to \(0.02\).
Reverse Process & Training Objective
A conditional U-Net \(\varepsilon_\theta\) predicts the added noise given the noisy action, observations, and diffusion timestep. The training minimizes:
Network Architecture
- Vision encoder: ResNet-18 (pretrained) processes each camera view independently, producing 512-dim feature vectors (3 × 512 = 1536 total).
- Proprioception MLP: Maps 14-dim joint states through Linear(14 → 64) → ReLU → Linear(64 → 128).
- Observation embedding: Concatenation and projection of vision (1536-dim) + proprioception (128-dim) → 2048-dim conditioning vector.
- Conditional U-Net: 4-layer encoder/decoder with Conv1D blocks, GroupNorm, Mish activations, sinusoidal timestep embedding, and cross-attention for observation conditioning.
Action Chunking & Inference
At inference, the model generates an action horizon of 16 timesteps but only executes 8 before re-planning (action chunking). This amortizes the ~2.1 s inference cost across 8 control steps, achieving an effective 15 Hz control frequency.
A command mux node arbitrates between emergency stop, teleop override, and diffusion policy outputs. The priority chain (E-stop > teleop > DP) ensures safe operation during autonomous execution.
System Architecture: ROS Computation Graph
The full system runs as a set of ROS nodes coordinating data collection, training, and inference. The diagram below shows the complete ROS computation graph during data collection mode, where the master arms are teleoperated while slave arms mirror the motion and cameras record observations.
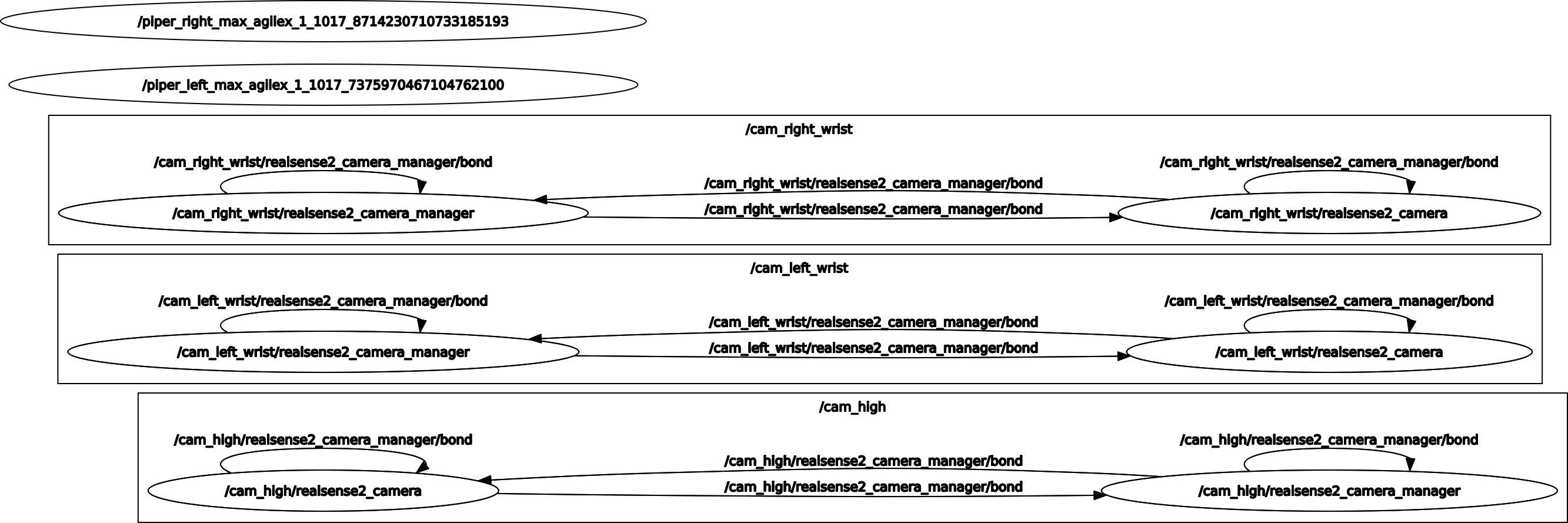
ROS computation graph showing the full system topology during data collection. Arm drivers, camera nodes, and the data recorder all communicate via ROS topics.
Data Collection Pipeline
The data collection workflow proceeds as follows:
- Initialize CAN bus interfaces for all four arms (both CAN adapters at 1 Mbit/s)
- Launch master arms in passive mode (
_mode:=0) and slave arms in active mode (_mode:=1) - Start three RealSense camera nodes for synchronized multi-view capture
- Operator performs the manipulation task on master arms; slave arms mirror in real-time
- Joint states (14-dim) and camera frames are recorded to ROS bags
- Post-processing converts bags to HDF5 format for training
Training Pipeline
Training uses the collected HDF5 datasets with the following steps:
- Load episode data: multi-view images, joint states, and action labels
- Apply data augmentation (random crop, color jitter) to camera views
- Sample random diffusion timesteps and add noise to ground-truth action chunks
- Forward pass through ResNet-18 encoders (per camera), proprioception MLP, and conditional U-Net
- Compute MSE loss between predicted and actual noise, backpropagate
Inference Pipeline
At inference time, the system operates in a closed loop:
- Capture current multi-view images and joint states
- Encode observations through frozen ResNet-18 and proprioception MLP
- Run 10 DDIM denoising steps (reduced from 100 for 10× speed-up) to generate an action chunk of 16 timesteps
- Execute the first 8 steps of the chunk, then re-plan (action chunking)
- A command mux node arbitrates between emergency stop, teleop override, and diffusion policy outputs with priority chain: E-stop > teleop > DP
System Specifications
| Parameter | Value |
|---|---|
| Arms | 4 × Piper 6-DOF + gripper |
| Cameras | 3 × Intel RealSense (RGB-D) |
| Observation horizon | 2 timesteps |
| Action horizon | 16 timesteps |
| Execution horizon | 8 timesteps |
| Inference time | ~2.1 s (10 DDIM steps) |
| Control frequency | 15 Hz (amortized) |
| ROS publishing rate | 200 Hz |
| Model size | ~50 MB |