Neural Network Pruning & Spurious Correlations
CS260D: Machine Learning with Distributional Shifts , UCLA
Investigated how neural network pruning affects models trained on datasets with spurious correlations,undesirable associations between class-irrelevant features and labels. While deep networks can exploit these shortcuts to achieve high average accuracy, they suffer poor worst-group accuracy on samples without the spurious feature. This work studies whether strategic pruning can mitigate this vulnerability across both supervised and contrastive learning settings.
Problem Setting
Spurious correlations arise when a dataset contains features that are statistically associated with labels but not causally relevant. For example, a classifier might learn to associate image background color with the digit class. Models trained via empirical risk minimization (ERM) tend to rely on these shortcuts, resulting in high average accuracy but poor performance on minority groups where the spurious feature is absent.
The central question is: does reducing network capacity through pruning force the model to discard spurious features in favor of more robust, core features?
Supervised Learning Experiments
- Dataset: SpuCo MNIST with controlled spurious feature correlations
- Model: SpuCoModel LeNet (2 convolutional + 2 fully connected layers)
- Training: Just Train Twice (JTT) , initial ERM training, error set identification, upsampled retraining
- Pruning: Layer-by-layer magnitude-based pruning at varying ratios (0 to 1)
Evaluation Metrics
- Worst-group accuracy: Performance on groups lacking the spurious attribute
- Average accuracy: Overall performance across all groups
- Spurious attribute predictability: Model's ability to predict the spurious feature (fairness indicator)
Contrastive Learning Experiments
- Dataset: Custom MNIST with added color channels (yellow, red, green, blue) as spurious features, with horizontal flip and random crop augmentations
- Architecture: 3-layer convolutional encoder + 2-layer projection head
- Training: TwoCropTransform contrastive objective encouraging similar instances to have aligned embeddings
- Evaluation: Linear probing on frozen representations for cluster separation quality
Key Results
Supervised Setting
- Accuracy remains stable up to ~70% pruning across all layers, demonstrating significant redundancy.
- Last-layer pruning produces the smallest drops in worst-group accuracy, suggesting the final layer encodes the most spurious features.
- Recommendation: aggressive pruning (high ratio) for the last layer, conservative pruning for earlier layers.
Contrastive Setting
- On Spurious MNIST, training accuracy exceeds validation accuracy (unlike plain MNIST), indicating heavy reliance on spurious color features.
- At 0.6 magnitude pruning: middle-layer (Layer 2) pruning pushes validation accuracy above training (~83%), suggesting removal of spurious feature pathways.
- At 0.9 magnitude pruning: last-layer pruning achieves maximum validation accuracy (~83.5%).
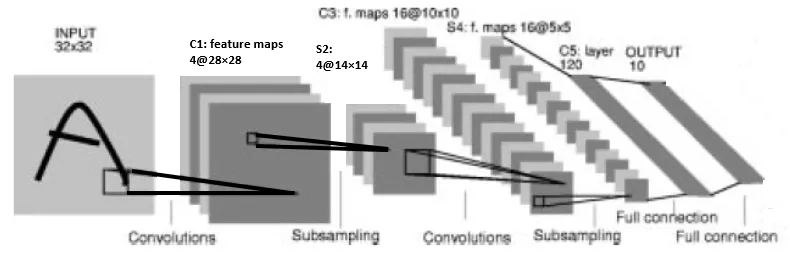
LeNet-4 architecture used for supervised learning experiments on SpuCo MNIST.

Supervised learning results on SpuCo MNIST: accuracy vs. pruning ratio across different layers.

Worst-group accuracy analysis showing the effect of pruning on spurious correlation robustness.

Custom MNIST dataset with added color channels (yellow, red, green, blue) as spurious features.
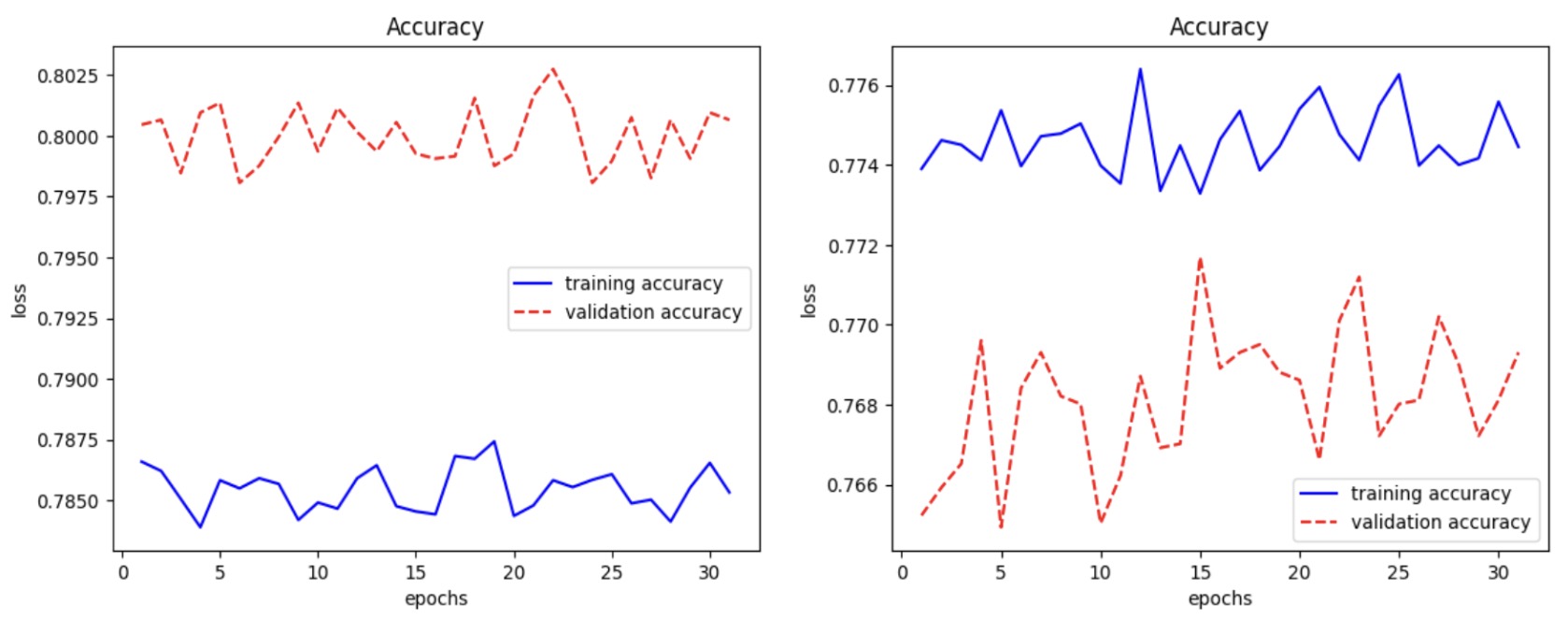
Contrastive learning embeddings without pruning: clusters show entanglement with spurious color features.
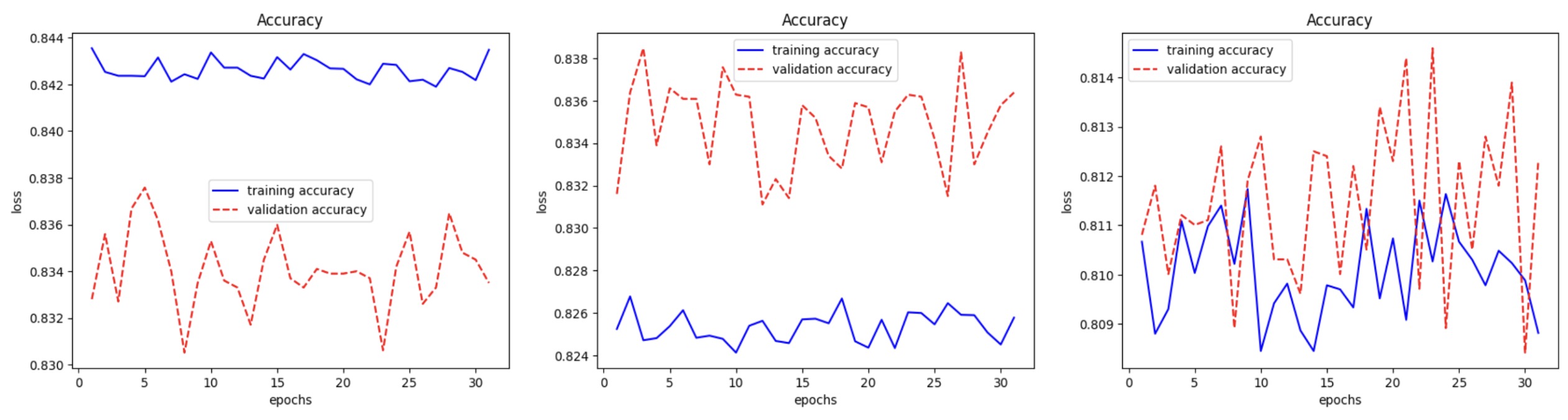
At 0.6 pruning: middle-layer pruning pushes validation accuracy above training (~83%), suggesting removal of spurious pathways.
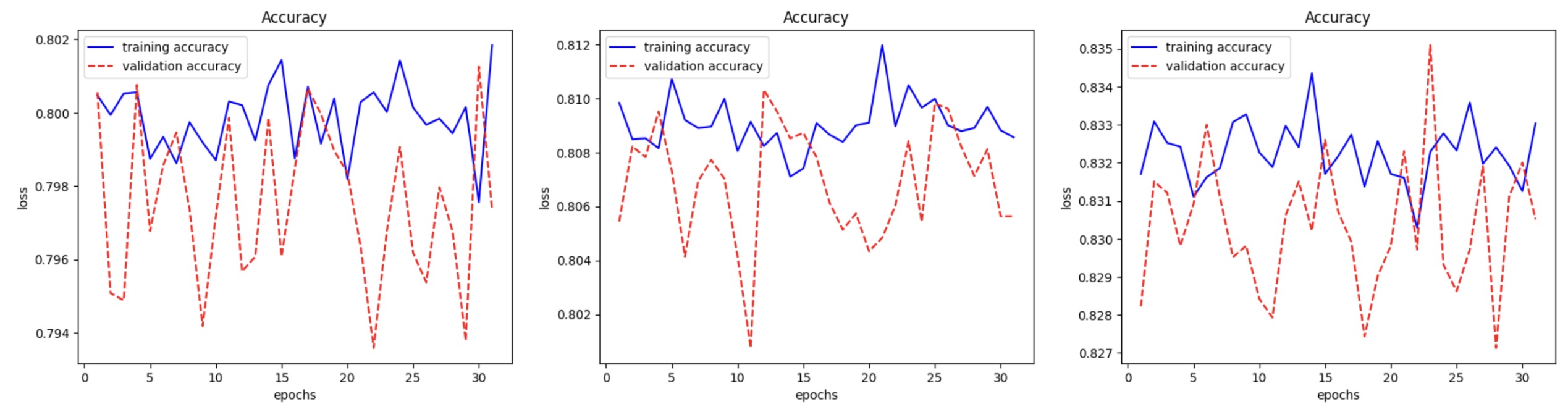
At 0.9 pruning: last-layer pruning achieves maximum validation accuracy (~83.5%).
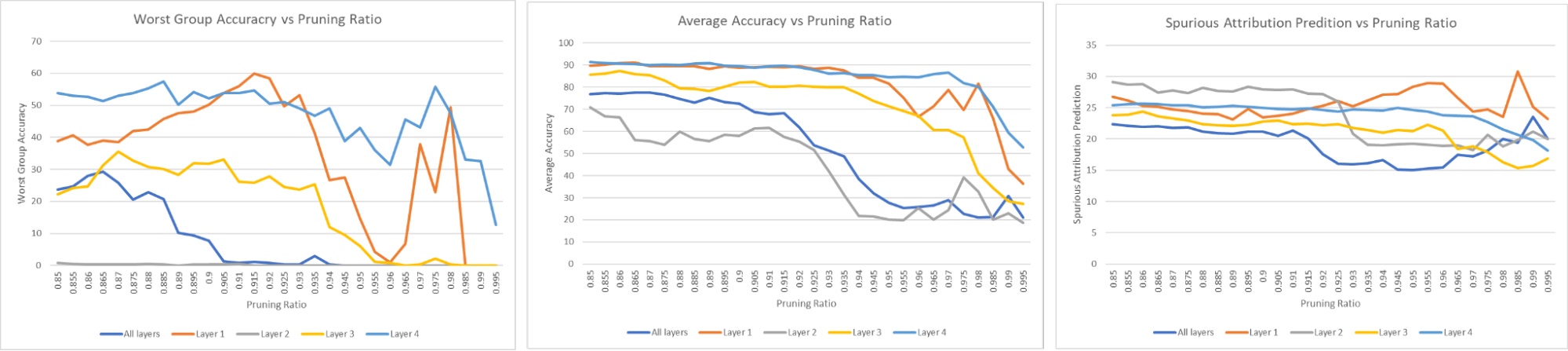
Layer-wise pruning sensitivity analysis across different pruning ratios.
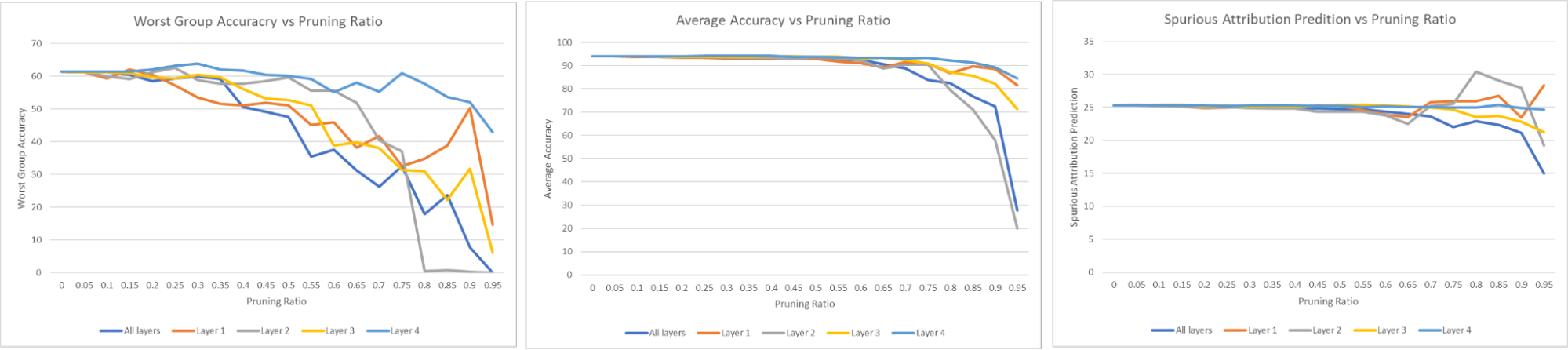
Comparison of pruning strategies on worst-group vs. average accuracy.
Conclusions
Pruning reveals a nuanced relationship with spurious correlations. While pruning generally reduces redundancy and improves efficiency, the layer and ratio matter significantly:
- Higher pruning ratios on the last layer produce the most effective results across both paradigms.
- At lower pruning ratios, middle-layer pruning is more beneficial in the contrastive setting.
- The penultimate and final layers appear to encode the strongest spurious feature representations, consistent with prior findings that retraining the last layer can improve robustness.