Benchmarking Data Quality in Imitation Learning
ICML DataWorld 2025 Workshop (presented), UCLA Robot Intelligence Lab
RINSE is a framework for evaluating and filtering demonstration quality in imitation learning using two complementary smoothness-based metrics: Spectral Arc Length (SAL) and Trajectory-Envelope Distance (TED). These metrics operate without policy training, rollouts, or dataset-global statistics, enabling efficient data curation before any learning begins.
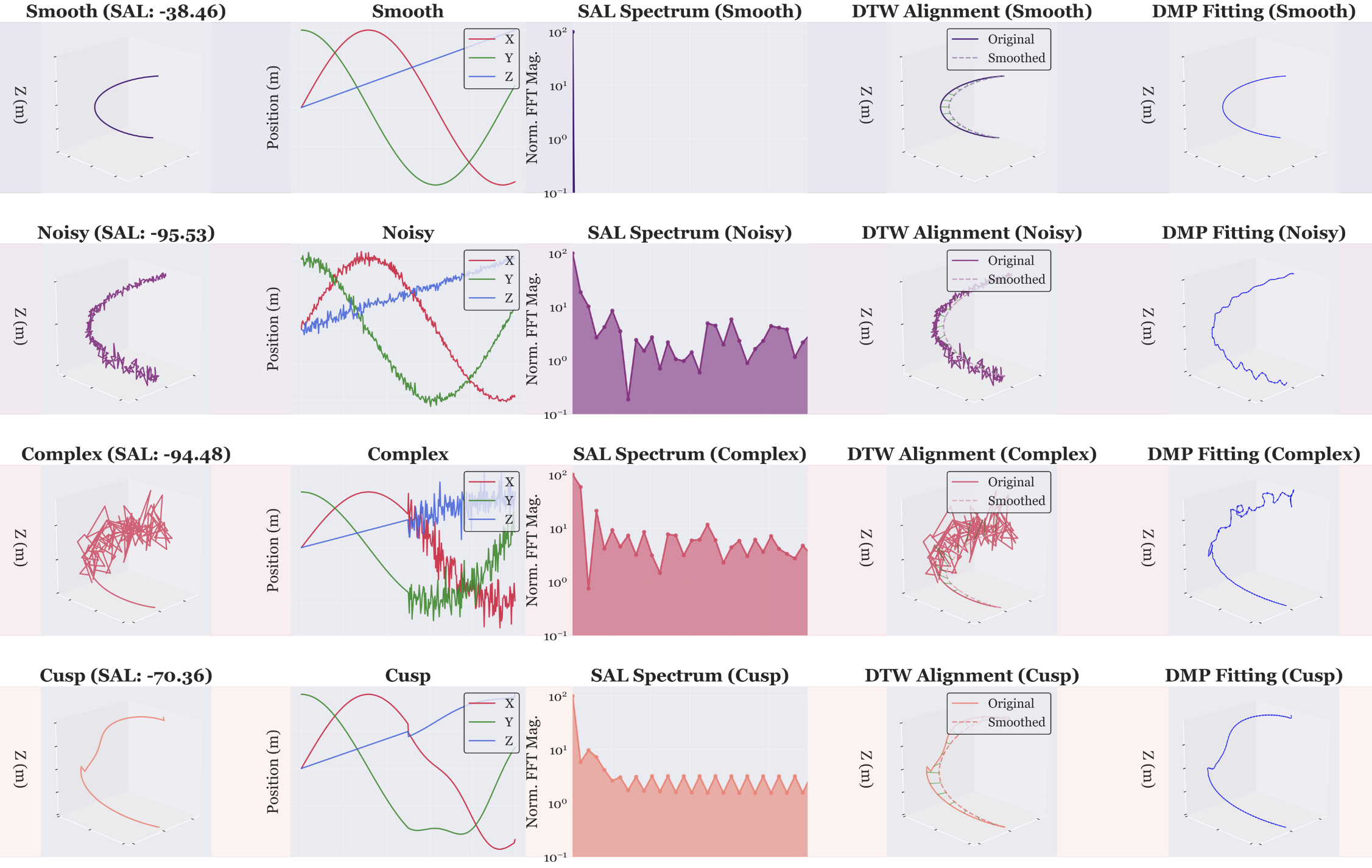
Method overview: SAL operates in the frequency domain on speed profiles, while TED measures geometric deviation from a smooth Bézier envelope with contact-aware partitioning.
Motivation
Behavioral cloning (BC) is fundamentally limited by demonstration quality. The BC policy loss decomposes as:
The second term is a noise floor \(\bar{\sigma}^2\) that cannot be reduced by training. With the BC regret bound \(J(\hat{\pi}) - J(\pi^*) \leq H^2 \varepsilon\), even modest reductions in per-step error amplify into substantial rollout improvements through the \(H^2\) compounding factor. RINSE targets this noise floor by identifying and removing low-quality demonstrations.
Quality Diagnostic: Data Collection Modality
Applied to the RTIS benchmark (5 manipulation tasks, 3 collection modalities), both SAL and TED consistently rank kinesthetic > VR > spacemouse, matching the downstream policy success ordering. Rate-controlled spacemouse introduces up to 4× larger TED scores compared to kinesthetic teaching.

SAL (higher = smoother) and TED (lower = smoother) for the Open Drawer task. Scores correlate with policy success across collection modalities.
Filtering: RoboMimic Benchmarks
Smoothness-based filtering on three RoboMimic benchmarks with Diffusion Policy (Transformer backbone). Demos are ranked by TED or SAL, and a budget of \(K\) top demonstrations is selected.
| Task | Source | |\(\mathcal{D}\)| | \(K\) | TED | SAL | Full |
|---|---|---|---|---|---|---|
| Square | mh | 300 | 50 | 75% | 72% | 76% |
| Square | better | 100 | 50 | 82% | 82% | 78% |
| Tool Hang | ph | 200 | 100 | 58% | 71% | 63% |
| Transport | mh | 300 | 50 | 46% | 55% | 39% |
| Transport | b-b | 50 | 25 | 36% | 54% | 42% |
SAL filtering achieves a +16% improvement on Transport (bimanual task with substantial free-space motion) using only 50 of 300 demos. On Tool Hang, SAL with half the demonstrations exceeds full-data performance by +8%. Filtered top-50 on Square converge to 75% success in ~40k steps vs ~450k for the full 300 demos (>10× convergence speed-up).
Filtering: Real-World Experiments
Evaluated on a U-Factory xArm 7-DOF robot with two RealSense cameras (wrist and side-mounted). All policies use Diffusion Policy (1D Conv UNet backbone), evaluated at epoch 50 over 25 randomized trials.
| Task | |\(\mathcal{D}\)| | \(K\) | Random | TED | SAL | Full |
|---|---|---|---|---|---|---|
| Push Block | 200 | 150 | 64% | 80% | 72% | 68% |
| Push Block | 200 | 100 | 59% | 88% | 84% | 68% |
| Push Block | 200 | 50 | 52% | 84% | 84% | 68% |
| Pick & Place | 80 | 40 | 55% | 76% | 68% | 76% |
TED filtering achieves +20% higher success on Push Block with half the data. At every subset size, TED outperforms random subsets by 16-32 percentage points, confirming that the quality ranking (not just subset size) drives improvement.
Filtering: Retrieval-Augmented Learning (LIBERO-10)
Integrated into the STRAP retrieval framework on LIBERO-10 (10 language-conditioned manipulation tasks). The top 400 SDTW candidates per query are re-ranked by TED or SAL, retaining the top 200.
| Method | Mug-MW | Moka | Soup-S | CCB | Mug-P | Stove | Bowl-C | Soup-C | Mug2 | Book-C | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| STRAP | 16 | 0 | 40 | 16 | 22 | 84 | 76 | 24 | 48 | 80 | 40.6 |
| +TED | 14 | 0 | 32 | 48 | 38 | 72 | 92 | 34 | 48 | 84 | 46.2 |
| +SAL | 14 | 0 | 44 | 8 | 34 | 68 | 84 | 40 | 58 | 100 | 45.0 |
TED+STRAP and SAL+STRAP improve aggregate success by +5.6% and +4.4% respectively. TED excels on contact-sensitive tasks (Cream-Cheese-Butter: +32%), while SAL excels on tasks with free-space motion (Book-Caddy: +20%).
Re-Mix Domain Reweighting
RINSE scores are used as soft quality weights within the Re-Mix framework for Group-DRO-style domain reweighting across 7 Open X-Embodiment domains. RINSE-weighted allocations achieve Spearman \(\rho \geq 0.89\) and cosine similarity \(\geq 0.989\) with Re-Mix base allocations, which are validated to improve downstream policy performance. All variants concentrate weight on the toto domain, identified as having the highest marginal training value.
Metric Complementarity
SAL excels at detecting free-space jitter (e.g., Transport task), while TED captures spatial artifacts near contact (e.g., Square task). Together they provide comprehensive trajectory quality assessment across different task structures.
SAL trajectory-filtered variance reduction across tasks
TED trajectory-filtered variance reduction across tasks
Video 1:
Policy rollout for the RoboMimic Square task: lift the square nut and place it on the peg with high precision
Video 2:
Policy rollout for the Push-T task: push the T block to the traced goal location
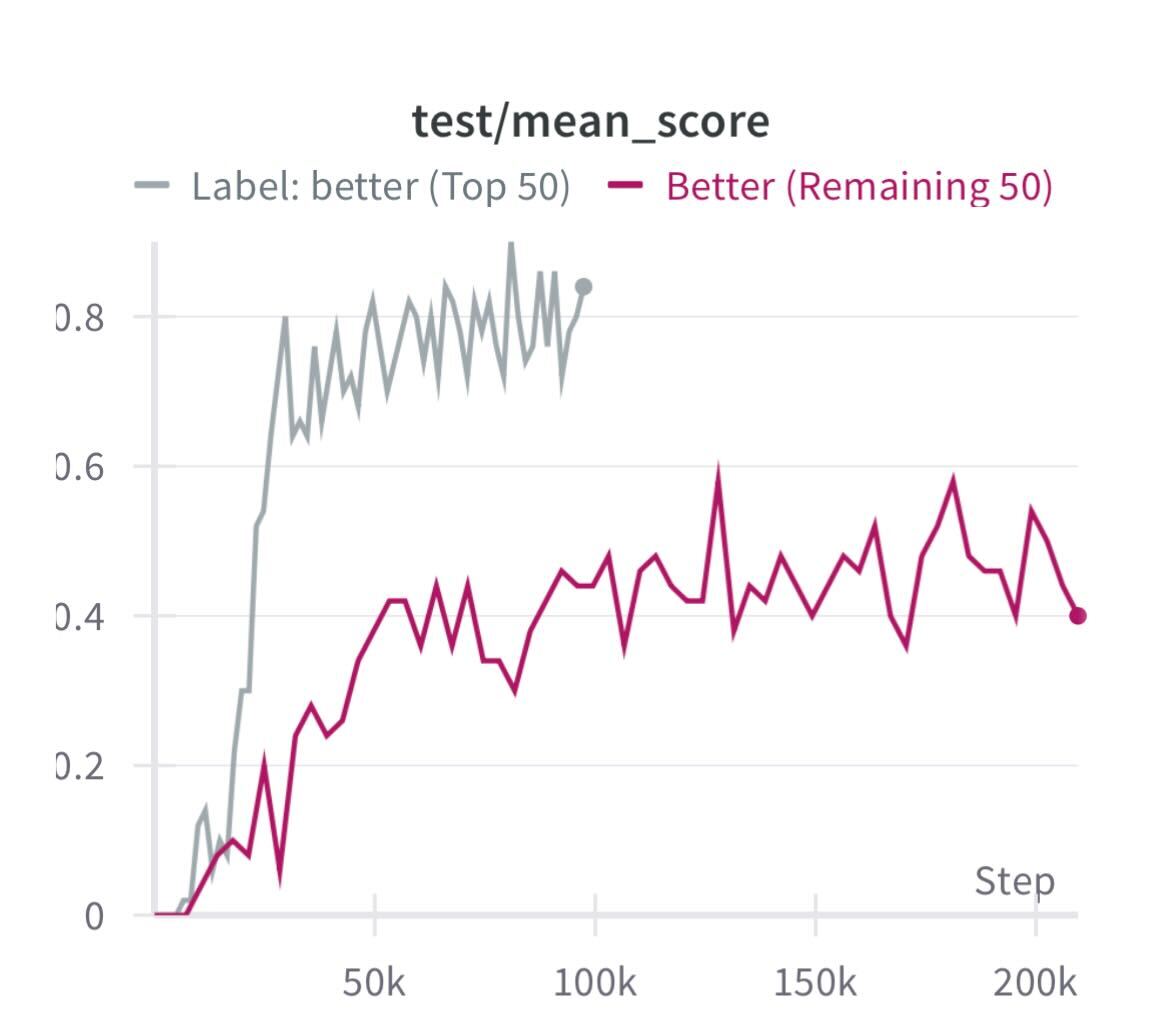
Mean score plots for the filtration test: filtered demos outperform the remaining set and even the full-dataset policy