Agile Autonomous Quadrotor Flight with Safety Constraints
For the IROS 2022 Safe Robot Learning Competition
Work done with Dr. M Vidyasagar FRS (IIT Hyderabad) and Dr. Srikanth Saripalli (Texas A&M University).
The goal is to achieve minimum-time flight for a Crazyflie quadrotor navigating through an environment with gates and obstacles. The competition injects additional perturbations (shifted gate positions, wind gusts), making robust control essential. We explored both classical and learning-based approaches in AirSim before deploying on physical hardware.
AirSim Experiments
- Stereo matching and obstacle detection for environmental awareness
- Reinforcement learning approaches tested: Deep Q-Network (DQN) and Proximal Policy Optimization (PPO)
- Safety policy: stop and wait whenever obstacles are within 0.2 m distance
- Safe flight distance achieved: approximately 46.1 m at conservative speeds
PPO Formulation
Action Space
Each motor \(i \in \{1, 2, 3, 4\}\) has a normalized thrust command \(f_i \in [0, 1]\). The action space is discretized into six levels per motor:
yielding \(6^4 = 1296\) discrete actions across the four rotors.
Observation Space
The 13-dimensional observation vector:
| Component | Dimension | Description |
|---|---|---|
| \(\mathbf{p}\) | \(\mathbb{R}^3\) | Position (x, y, z) |
| \(\mathbf{v}\) | \(\mathbb{R}^3\) | Linear velocity |
| \(\mathbf{a}\) | \(\mathbb{R}^3\) | Linear acceleration |
| \(\psi\) | \(\mathbb{R}\) | Yaw angle (radians) |
| \(\boldsymbol{\omega}\) | \(\mathbb{R}^3\) | Angular velocity |
Reward Function
The first term provides a proximity bonus that saturates at zero far from the target and reaches a maximum of 1 at the goal. The penalty terms \(C_\theta \|\boldsymbol{\theta}\|\) and \(C_\omega \|\boldsymbol{\omega}\|\) discourage unstable spinning and aggressive attitude changes. A collision penalty of \(-5\) is applied upon contact with obstacles.
Training Configuration
| Hyperparameter | Value |
|---|---|
| Discount factor \(\gamma\) | 0.99 |
| Learning rate \(\alpha\) | \(3 \times 10^{-4}\) |
| Clip range \(\epsilon\) | 0.2 |
| GAE \(\lambda\) | 0.95 |
| Batch size | 64 rollout steps |
| Network | 2 hidden layers, 64 units each, ReLU |
| Training seeds | 50 random seeds, 500k steps each |
Results (PPO, 50 seeds)
| Level | Success Rate | Mean Time (sec) |
|---|---|---|
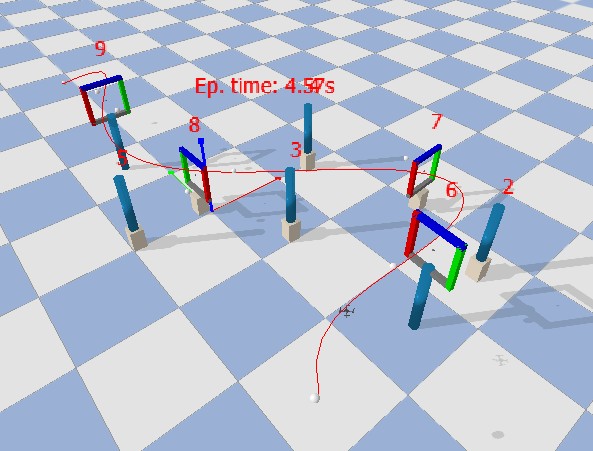
| 0 (non-adaptive, fixed gates) | 100% | 4.5 |
| 1 (adaptive, randomized gates + wind) | 84% | 5.3 |
At Level 0 (fixed gate positions, no wind), the PPO agent achieves 100% success with a mean traversal time of 4.5 seconds. At Level 1, where gate positions are randomized and wind gusts are injected, performance degrades to 84% with increased mean time of 5.3 seconds due to corrective maneuvers.
Follow this repository for more details.