EKF and Non-linear Least-Squares Optimization Based SLAM
For IEEE RAS Winter School for SLAM in Deformable Environments
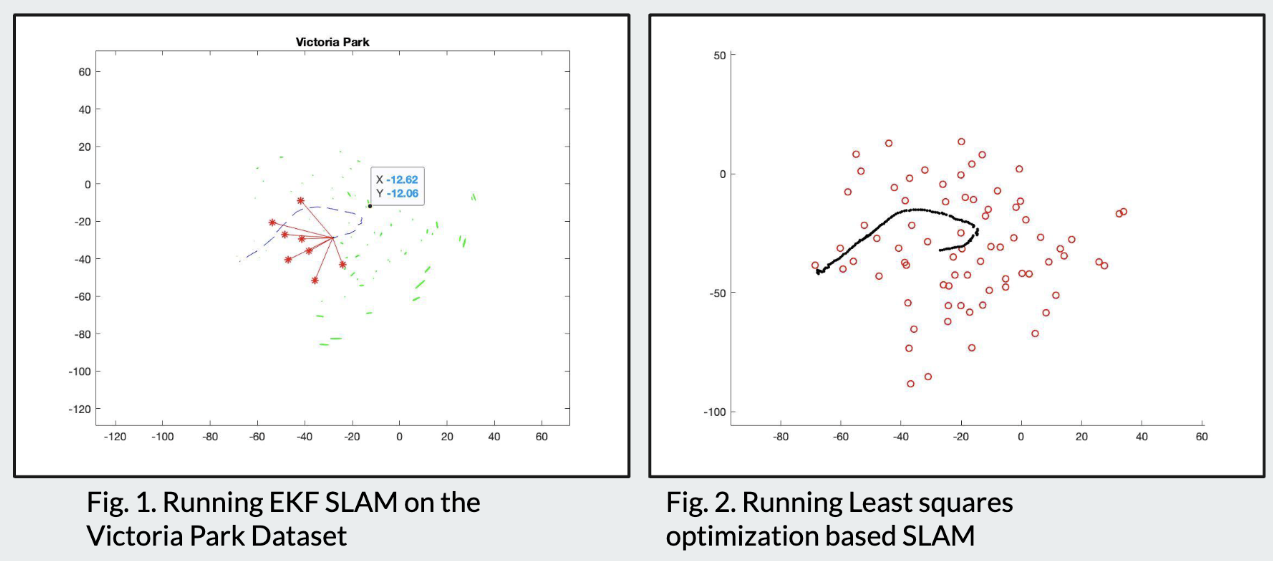
Implemented and compared two classical SLAM approaches on the Victoria Park Dataset: filter-based EKF-SLAM and optimization-based non-linear least-squares SLAM (Graph SLAM).
EKF-SLAM
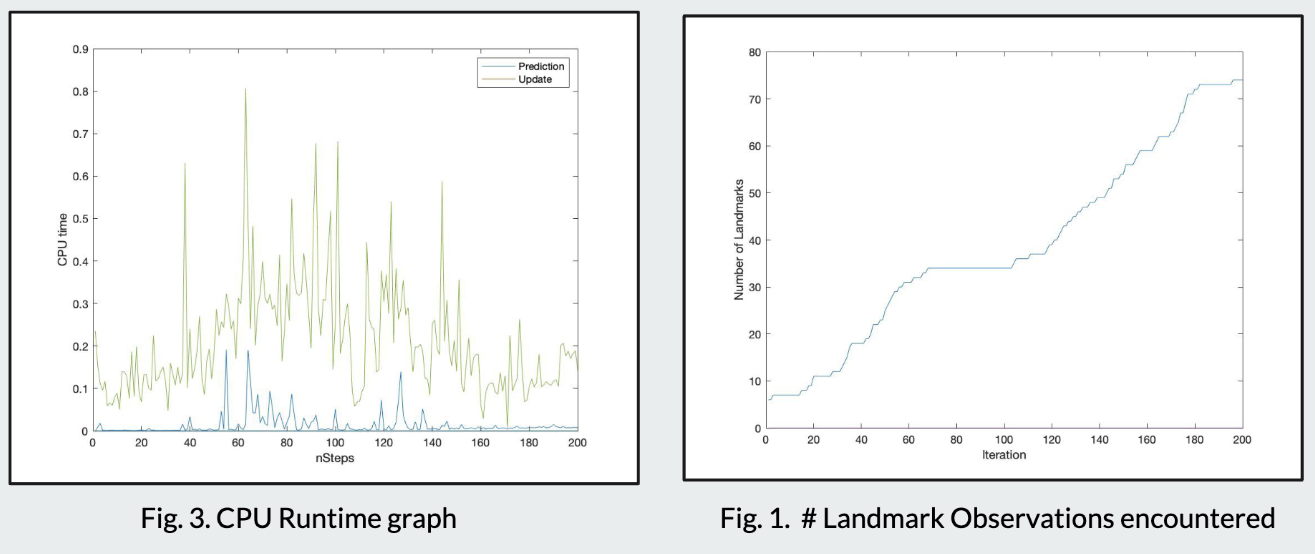
The Extended Kalman Filter maintains a joint state vector of the robot pose and all landmark positions, updated incrementally as new observations arrive.
State Vector
The augmented state vector concatenates the robot pose \(\mathbf{x}_r = [x, y, \theta]^\top\) with \(N\) landmark positions:
Prediction Step
Given control input \(\mathbf{u}_t = [v_t, \omega_t]^\top\) (velocity and angular velocity), the motion model is:
The covariance prediction uses the Jacobian \(\mathbf{F}_t\) of the motion model:
where \(\mathbf{Q}_t\) is the process noise covariance.
Update Step
For a range-bearing observation \(\mathbf{z} = [r, \phi]^\top\) of landmark \(j\):
where \(\mathbf{H}_t\) is the observation Jacobian, \(\mathbf{R}_t\) is the measurement noise, and \(\mathbf{K}_t\) is the Kalman gain.
Graph SLAM (Non-linear Least Squares)
The optimization-based approach constructs a factor graph where nodes represent robot poses and landmark positions, and edges encode odometry and observation constraints. The objective minimizes the sum of squared Mahalanobis distances:
where the weighted norm is \(\|\mathbf{e}\|^2_{\boldsymbol{\Omega}} = \mathbf{e}^\top \boldsymbol{\Omega} \, \mathbf{e}\) with information matrix \(\boldsymbol{\Omega}_{ij}\). This is solved iteratively using the Gauss-Newton algorithm, which linearizes the constraints at each step:
Comparison
| Aspect | EKF-SLAM | Graph SLAM |
|---|---|---|
| Complexity per step | \(\mathcal{O}(N^2)\) | \(\mathcal{O}(N)\) amortized |
| Memory | Dense covariance \(\mathcal{O}(N^2)\) | Sparse factors \(\mathcal{O}(N)\) |
| Consistency | Approximation errors accumulate | Global optimization, more consistent |
| Loop closure | Difficult to incorporate | Natural via graph edges |
| Linearization | Single linearization point | Re-linearization at each iteration |