DDP-Based Solver for Optimal Control Under Contact Sequences
Course project for M270C: Optimal Control
Implemented BOX-FDDP (Box-constrained Feasibility-Driven Differential Dynamic Programming) for various dynamical systems using the Multi-Contact Optimal Control Problem (MCOP) formulation. The solver is built on the Crocoddyl framework and applied to humanoid whole-body manipulation and quadruped locomotion problems.
Problem Formulation
The MCOP seeks to minimize a cost functional over a finite horizon \(T\) subject to system dynamics and control bounds:
subject to \(\mathbf{x}_{t+1} = f(\mathbf{x}_t, \mathbf{u}_t)\) and \(\mathbf{u}_{\min} \leq \mathbf{u}_t \leq \mathbf{u}_{\max}\), where \(\mathbf{Q}\) and \(\mathbf{R}\) are state and control weight matrices, and the cost includes waypoints as desired poses and velocities.
DDP Backward Pass
The standard DDP backward pass computes feedback gains by expanding the Q-function around the current trajectory. The control update is:
where the feedback gain \(\mathbf{K}_t\) and feedforward term \(\mathbf{k}_t\) are:
BOX-FDDP: Feasibility-Driven Approach
Standard Box-DDP projects control updates onto the feasible set after computing the full update, which can lead to numerical instability. BOX-FDDP instead modifies the backward pass to compute updates under relaxed feasibility constraints, applying an early feasibility projection:
where \(\Pi\) is the projection operator onto the box constraint set. This early projection ensures that control updates remain feasible throughout the optimization, improving convergence stability. The feasibility gap is tracked and drives the step-size selection, allowing the solver to trade off optimality and constraint satisfaction dynamically.
Applications
- Quadcopter: Reaching target locations, performing looping maneuvers, and passing through narrow gaps in walls
- Humanoid (Talos): Whole-body manipulation with constrained torques, single-leg balancing (Taichi pose), and sequential task completion
- Quadruped (ANYmal-C): Trotting locomotion with coordinated leg contact sequences
Results: Box-DDP vs. BOX-FDDP
On the ANYmal-C quadruped robot, BOX-FDDP produces smooth, harmonious trajectories with coordinated leg motions, while standard Box-DDP generates jerky trajectories with loops and poor inter-leg coordination. This improvement stems directly from the early projection of control commands within the feasibility-driven approach.
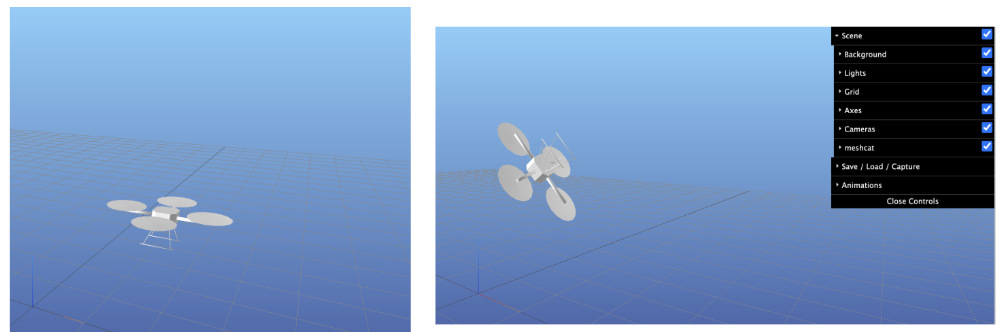
Quadcopter reaching a target location, performing looping maneuvers, and passing a narrow gap in a wall

(Left) Whole-body manipulation with bounded torques. (Center) Unbounded torques. (Right) Talos balancing on a single leg (Taichi). Center panels show parameter updates for initial iterations.
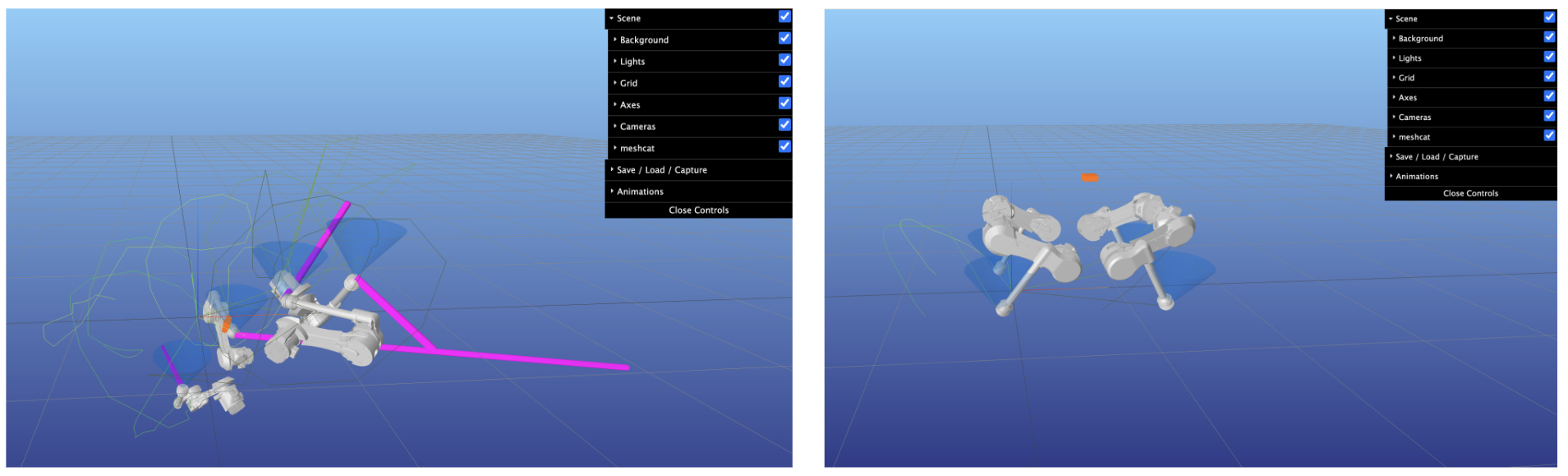
Box-DDP (left) vs BOX-FDDP (right) on ANYmal-C. BOX-FDDP produces smooth, coordinated trajectories while Box-DDP generates jerky motions with poor leg harmony.