Creating Persona Chatbots (with a focus on evaluation)
CS263A: Natural Language Processing, UCLA
Explored different aspects of persona injection in open-ended dialogue systems using prompt tuning techniques: in-context learning and chain-of-thought (CoT) prompting. The baseline model is Mistral 7B, and we compare persona-injected outputs against GPT-3.5, GPT-4, Llama 3, and Phi.
Prompt Tuning Techniques
- In-Context Learning: Example persona-consistent dialogues provided within the prompt, allowing the model to adapt behavior based on demonstrated examples without parameter updates.
- Chain-of-Thought (CoT): The model reasons step-by-step about persona consistency, explicitly considering the persona's background, speech patterns, and knowledge boundaries before generating a response.
- Combined (CoT + In-Context): Both techniques applied together for maximum persona alignment.
Evaluation Framework
- LLMEval (GPT-4 as judge): Automated evaluation of fluency and coherency by prompting GPT-4 to score generated dialogues on semantic consistency with the assigned persona.
- MMLU: 57-subject benchmark spanning STEM, humanities, and social sciences to measure whether persona injection degrades general reasoning ability.
- Toxicity and Bias (HDS Score): Harmful content variance across demographic groups to ensure persona-injected models do not introduce disproportionate toxicity.
Results
| Metric | Model / Condition | Score |
|---|---|---|
| Fluency & Coherency (GPTEval) | Mistral 7B | 3.18 |
| GPT-3.5 | 3.32 | |
| GPT-4 | 3.32 | |
| Llama 3 | 3.79 | |
| Phi | 3.95 | |
| Reasoning (MMLU) | Baseline | 47.13% |
| CoT | 45.83% | |
| CoT + In-Context | 43.24% | |
| Perplexity | Mistral 7B | 13.9 |
| Toxicity | GPT-2 | 0.029 ± 0.0066 |
| Our Model | 0.104 ± 0.047 | |
| HDS Score | GPT-2 | 0.076 |
| Our Model | 0.0258 |
Key Observations
- All persona-injected models achieved higher fluency and coherency than human-generated dialogues, with Phi scoring highest at 3.95.
- MMLU scores decreased with stronger persona alignment (47.13% to 43.24%), suggesting a trade-off between persona fidelity and general reasoning.
- Our model showed increased but controlled toxicity (0.104 vs. GPT-2's 0.029), while the HDS score dropped from 0.076 to 0.0258, indicating reduced harmful content variance across demographic groups.
Follow this repository for more details.
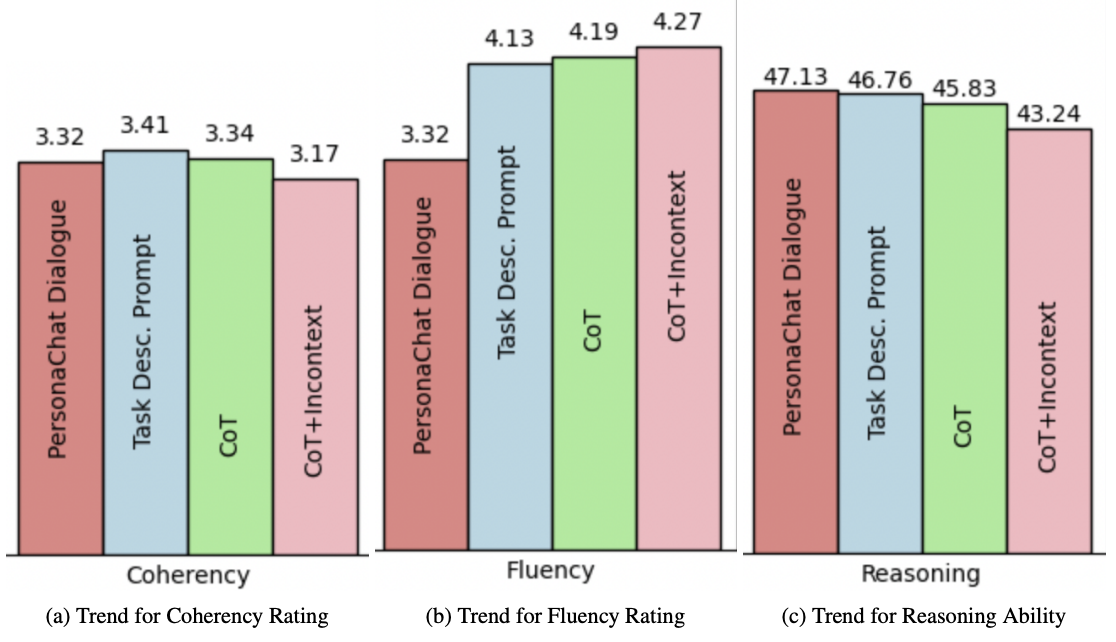
Figure (a): Coherency score trend. Figure (b): Fluency score trend for GPT4Eval.
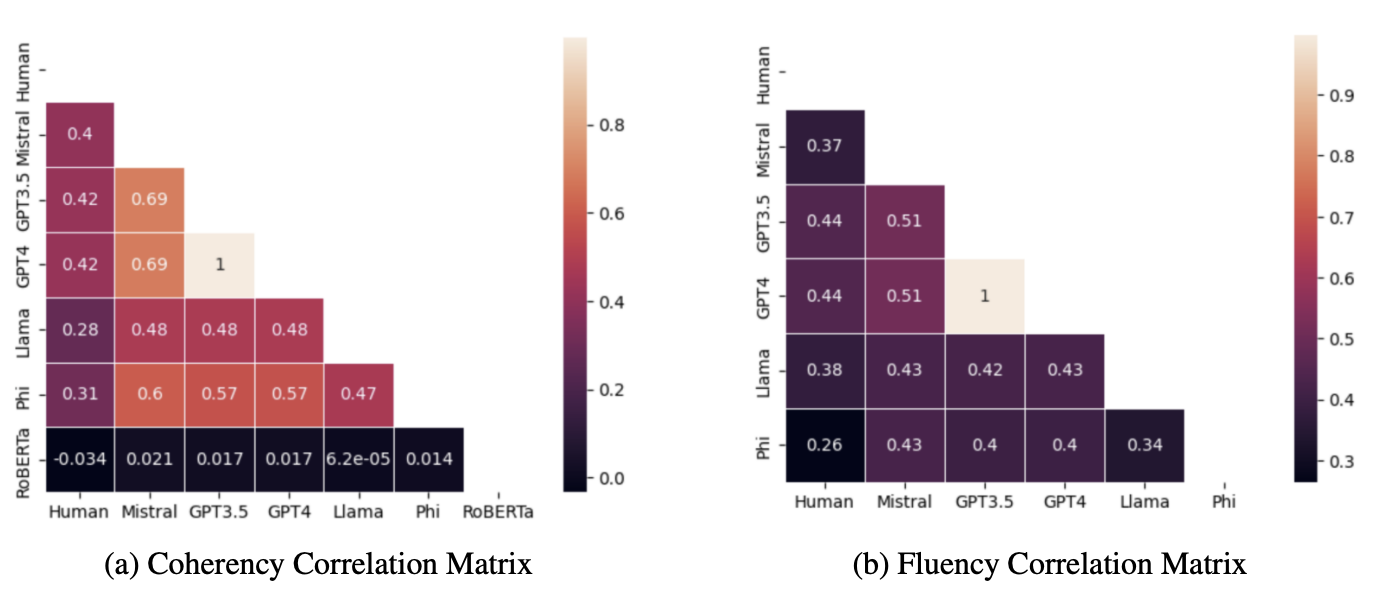
Correlation matrices for (a) coherency and (b) fluency across models and human evaluation. Lighter colors indicate higher correlation.
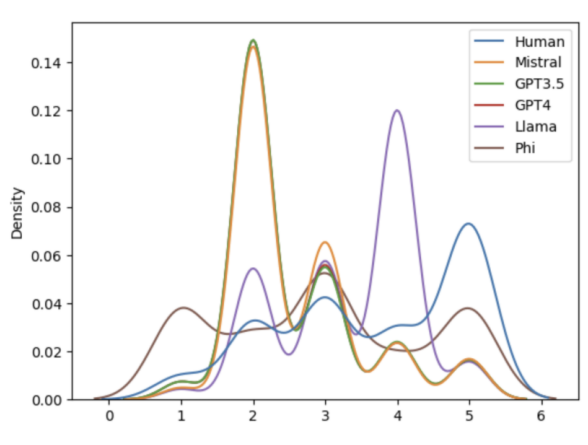
Kernel density estimate plots of coherency score distribution across models and human evaluators.